breakout = function(n_fellows, n_facils = 5){
# Takes in number of fellows and returns
# a possible permutation based on number of facilitators
gpSize = n_fellows%/%n_facils
remainder = n_fellows%%n_facils
# Determine distribution of groups
gpDist = rep(gpSize, n_facils)
if (remainder>0){gpDist[1:remainder] = gpDist[1:remainder] + 1}
group = NULL
for (i in 1:length(gpDist)){
group = c(group, rep(LETTERS[i], gpDist[i]))
}
dist = cbind.data.frame(id = sample(1:n_fellows, size=n_fellows),
group)
return(dist)
}Recently, I had the opportunity to join a fellowship with 27 other fellows. As part of the fellowship, we would meet for regular discussions once a week with the guidance of 5 facilitators. The program has been immensely rewarding so far - but in this post I will discuss a probability problem that I’ve been pondering over since the first meeting.
The problem is as follows: Every week for 10 weeks, all 28 fellows (assuming no absentees, but this may be explored later) and 5 (barring absentees again) facilitators meet for a discussion. Each meeting will have at least one breakout session, where the 28 fellows will be separated into the same number of groups as there are facilitators - so usually, 5 - and have a discussion on the assigned readings. The allocation of fellows is independent between each breakout session. The organisers of the fellowship were concerned if there were enough opportunities for everyone to get to know each other during the breakout sessions.
We can address that question from two different angles. We can fix the number of breakout rounds in total and observe the distribution of the simulated interactions. With this we can ask how many times would the same two people interact with each other, and how many people would not have met. The alternative is to keep simulating until everyone has interacted with every other person at least once, and observe the number of rounds required.
I’m sure there are solutions based in permutations and combinatorics that can derive an exact solution to the questions above. My personal take is that not only are these solutions complicated and tedious, the results may also not be helpful. Having an understanding of the probabilistic distribution of the answers would be much more interesting and interpretable to account for random effects which happen all the time. To that end, I present my solution below with supplementary code in R.
Defining the breakout function
First, I defined a function that takes in the number of fellows n_fellows and number of facilitators n_facils and outputs a possible permutation of the fellows in the number of groups equal to n_facils. In other words, it randomly assigns a group (A,B,C,D,E,…) to each fellow. We will rely on this function to simulate the answer to our questions.
Simulating interactions over a fixed number of breakout rounds
The first angle focuses on the number of interactions between fellows after a fixed number of breakout rounds. To do this we first specify the essential parameters of the model. Here we assumed the n_facils to be fixed at 5.
n_fellows = 28 # Number of fellows
N = 1000 # Number of simulations
rounds = 20 # Number of breakout roundsTo track the total number of interactions between two particular fellows, we can store the results of each breakout round in a matrix met, which is initialised with the number of rows and columns equal to n_fellows. The simulation then proceeds as follows: at the start of every round of simulation, we set all interaction counts to 0 - that is, met is a 0 matrix. Then the breakout rounds will be simulated and the interaction between members of the same group in each round will increase by 1. At the end of the 20 breakout rounds, met will contain the number of interactions between each of the fellows.
met_null = rep(NA, N)
met_mean = rep(NA, N)
for (n in 1:N){
met = matrix(0L, nc=n_fellows, nr=n_fellows)
for (round in 1:rounds){
dist = breakout(n_fellows)
# Check to see if fellows met, if met then
# their corresponding entry in met matrix increases by 1
for (gp in dist$group %>% unique){
fellows = dist %>% filter(group == gp) %>% pull(id)
for (i in fellows){
for (j in fellows){
met[i,j] = met[i,j] + 1
}
}
}
}
met_mean[n] = ((rowSums(met) - (rounds))/n_fellows) %>% mean
met_null[n] = sum(met[upper.tri(met, diag=FALSE)] == 0)
}We can generate quite interesting inferences from the met matrices generated by the 1000 rounds of simulation. In the code above, met_null calculates at each round the number of interactions not made, i.e. when two particular fellows have not met. This is computed by taking the upper triangular matrix of met and counting the number of 0’s, that is, the number of no interactions. Also, met_mean tells us the average number of times any two fellows have had an interaction.
met_mean is constant over each simulation and equal to 3.32. This means that on average, each fellow will meet every other fellow for 3.32 times. I don’t yet have an explanation for why it remains constant, but I think that the random effects over all the simulations are nullified by taking the mean of the number of interactions. I might be wrong.
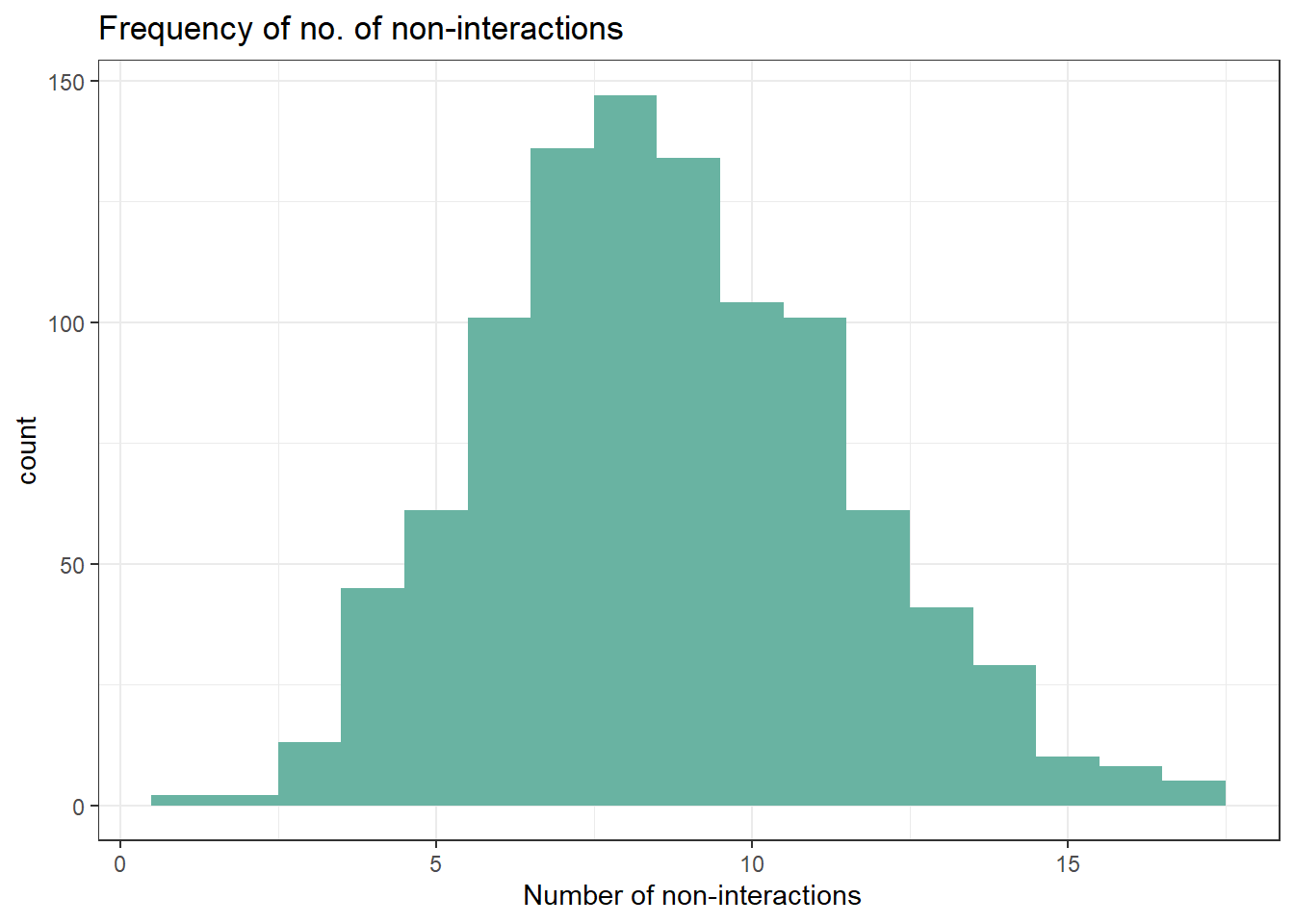
The histogram of the number of no-interactions, or met_null, is plotted above. It seems that for 20 breakout rounds, on average there can be 10 missed interactions - meaning 10 pairs of interactions between fellows will not materialise. This is quite interesting to note - out of a possible 378 interactons (taking 27+26+25+…+1), only around 2.6% of interactions are missed. It might reflect a high level of success in helping fellows establish interactions with one another.
Simulating the number of breakout rounds needed for every fellow to meet
Now instead of fixing the number of breakout rounds at 20, lets consider the number of breakout rounds it takes for every fellow to interact at least once. This would require every simulation to run a ‘while’ loop to keep simulating breakout rounds (in what might be the worst zoom-nightmare) until every fellow has met each other at least once. The code is attached below.
As with the previous simulation, the met matrix stores the interactions between each of the 28 fellows. However, the difference here is that it only has indicator (T/F) variables to store whether or not a pair of fellows have met, since we are not interested in the number of times they interacted. Similar to the previous simulation, when fellows are split into breakout groups, the matrix entry corresponding to their own and all their group mates will change to 1, indicating that they have interacted. The breakout groups will continue to be split over the ‘while’ loop, which runs until the total number of interactions exceeds n_fellows^2, which is sum of all entries in met when every fellow has met each other at least once.
counts = rep(NA, N)
for (iter in 1:N){
# initialise a nxn identity matrix to store 'met'
met = matrix(0L, nc=n_fellows, nr=n_fellows)
# randomly allocate groups each time
counter = 0
# loop until everyone has met each other at least once
while (sum(met) < n_fellows^2){
dist = breakout(n_fellows)
# Check to see if fellows met, if met then
# their corresponding entry in met matrix = 1
for (gp in dist$group %>% unique){
fellows = dist %>% filter(group == gp) %>% pull(id)
for (i in fellows){
for (j in fellows){
met[i,j] = 1
}
}
}
counter = counter + 1
}
counts[iter] = counter
}counts contains the number of breakout rounds required for every fellow to meet at least once in each simulation. The distribution of counts is plotted below.
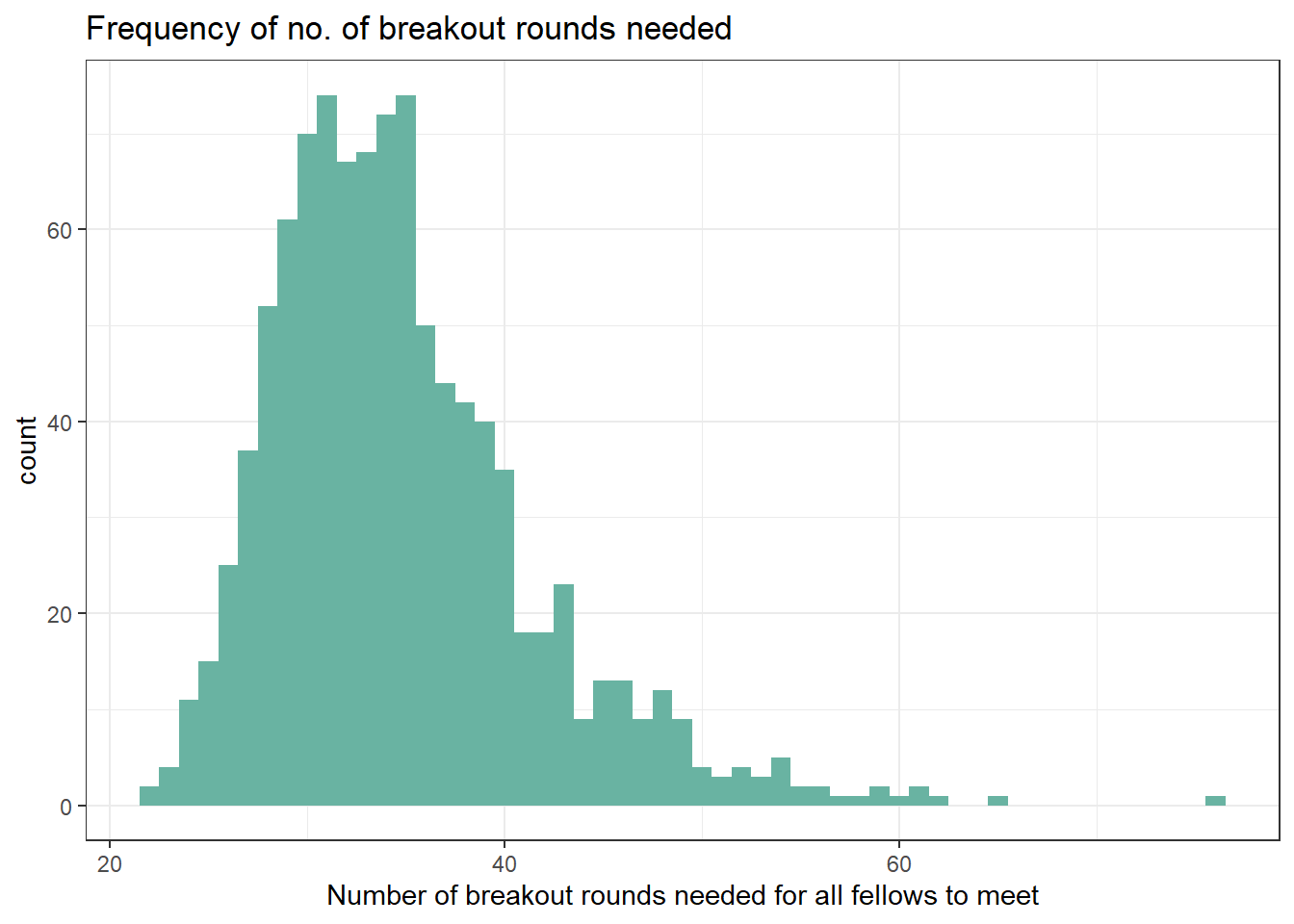
We see that the number of breakout rounds needed for all fellows to meet has a wide range, from 22 to 71, with the mean concentrated around 35. This means that it would require an average of 3.5 breakout sessions every week for every fellow to meet each other at least once.
To understand both simulations, I conclude that although the results suggest that it takes on average 35 breakout sessions for all fellows to meet at least once, having 20 breakout sessions already has a high coverage of close to 97%. Pursuing an objective for every fellow to meet each other at least once might not be worth the cost of extending an additional 15 or so breakout sessions. As a caveat, the limitations of the simulations are clear - the number of interactions does not tell us anything about the quality of interactions that the fellows have, which is difficult to quantify in and of itself. At its core, the fellowship should prioritise the quality of interactions and discussions over the number of links created in the social network.
This was quite an entertaining and insightful exercise in simulation, and its comforting to know that I can solve some complex problems with simulation instead of probability theory.